

 智东西
智东西
智东西7月28日报道,刚刚,阿里开源视频生成模型通义万相Wan2.2,包括文生视频Wan2.2-T2V-A14B、图生视频Wan2.2-I2V-A14B和统一视频生成Wan2.2-IT2V-5B三款模型。
其中,文生视频模型和图生视频模型为业界首个使用MoE架构的视频生成模型,总参数量为27B,激活参数14B,在同参数规模下可节省约50%的计算资源消耗,在复杂运动生成、人物交互、美学表达等维度上取得了显著提升。5B版本统一视频生成模型同时支持文生视频和图生视频,可在消费级显卡部署,是目前24帧每秒、720P像素级的生成速度最快的基础模型。

▲通义万相Wan2.2生成的视频
此外,阿里通义万相团队首次推出电影级美学控制系统,将光影、构图、色彩等要素编码成60多个直观的参数并装进生成模型。Wan2.2目前单次可生成5s的高清视频,可以随意组合60多个直观可控的参数。
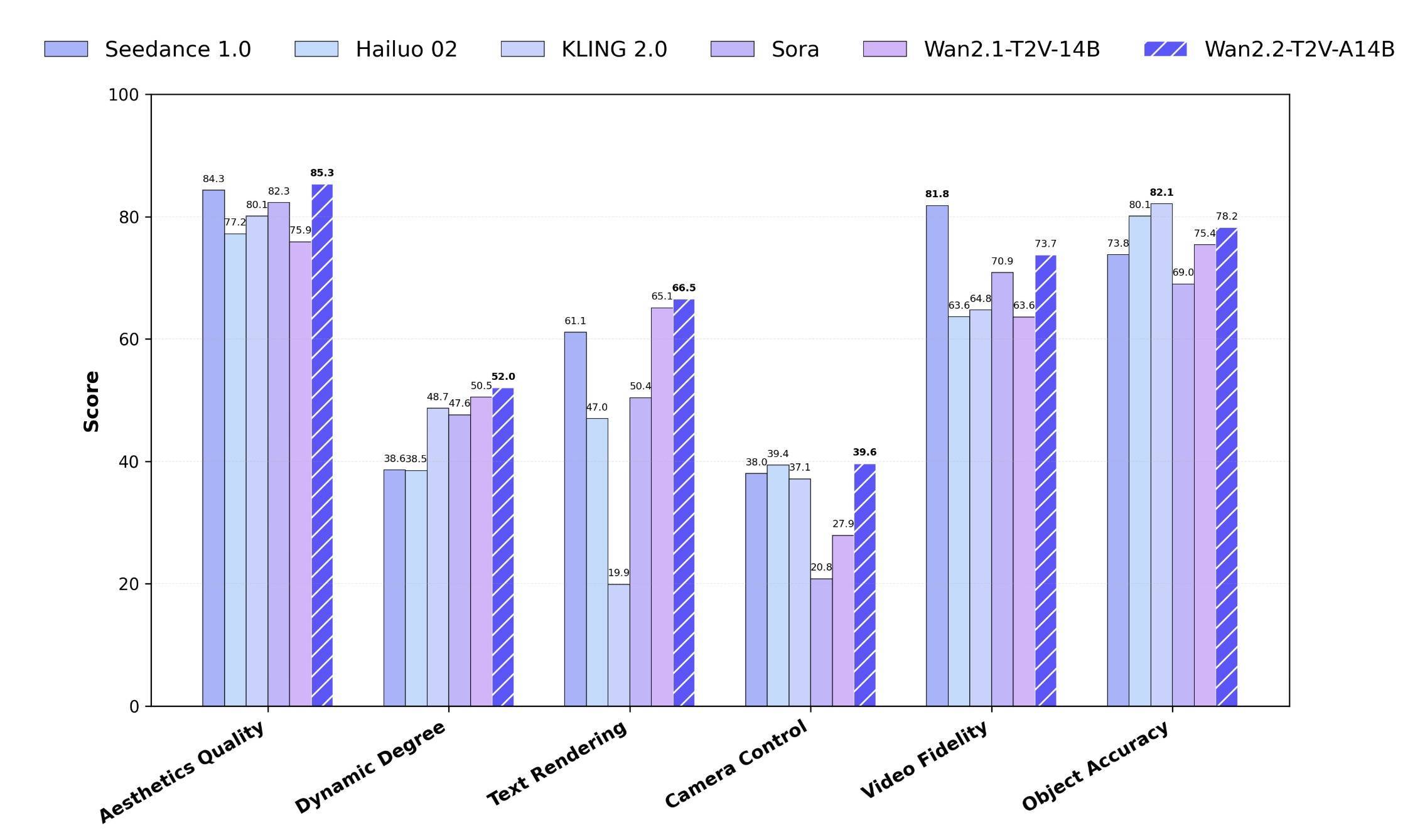
官方测试显示,通义万相Wan2.2在运动质量、画面质量等多项测试中超越了OpenAI Sora、快手Kling 2.0等领先的闭源商业模型。
业界首个使用MoE架构的视频生成模型有哪些技术创新点?5B版本又是如何实现消费级显卡可部署的?通过对话通义万相相关技术负责人,智东西对此进行探讨解读。
目前,开发者可在GitHub、HuggingFace、魔搭社区下载模型和代码,企业可在阿里云百炼调用模型API,用户还可在通义万相官网和通义APP直接体验。
GitHub地址:
https://github.com/Wan-Video/Wan2.2HuggingFace地址:https://huggingface.co/Wan-AI魔搭社区地址:https://modelscope.cn/organization/Wan-AI一、推出首个MoE架构视频生成模型,5B版本消费级显卡可跑根据官方介绍,通义万相Wan2.2的特色包括光影色彩及构图达到电影级,擅长生成复杂运动等,首先来看几个视频生成案例:
提示词1:Sidelit, soft light, high contrast, medium shot, centered composition, clean single subject frame, warm tones. A young man stands in a forest, his head gently lifted, with clear eyes. Sunlight filters through leaves, creating a golden halo around his hair. Dressed in a light-colored shirt, a breeze plays with his hair and collar as the light dances across his face with each movement. Background blurred, featuring distant dappled light and soft tree silhouettes.
(侧光照明,光线柔和,高对比度,中景镜头,居中构图,画面简洁且主体单一,色调温暖。一名年轻男子伫立在森林中,头部微微上扬,目光清澈。阳光透过树叶洒落,在他发间勾勒出一圈金色光晕。他身着浅色衬衫,微风拂动着他的发丝与衣领,每一个细微的动作都让光影在他脸上流转跳跃。背景虚化,隐约可见远处斑驳的光影和树木柔和的剪影。)
视频输出的gif截取:

提示词2:A man on the run, darting through the rain-soaked back alleys of a neon-lit city night, steam rising from the wet pavement. He’s clad in a drenched trench coat, his face etched with panic as he sprints down the alley, constantly looking over his shoulder. A chase sequence shot from behind, immersing the viewer deeply, as if the pursuers are right behind the camera lens.
(一个在逃的男人,在霓虹灯点亮的城市夜色中,冲过被雨水浸透的后巷,潮湿的路面上蒸腾起雾气。他裹着一件湿透的风衣,脸上刻满惊慌,顺着巷子狂奔,不断回头张望。这段追逐戏从后方拍摄,将观众深深带入情境,仿佛追捕者就在镜头背后。)
视频输出的gif截取:

提示词3:A purely visual and atmospheric video piece focusing on the interplay of light and shadow, with a corn train as the central motif. Imagine a stage bathed in dramatic, warm spotlights, where a corn train, rendered as a stark silhouette, moves slowly across the space. The video explores the dynamic interplay of light and shadow cast by the train, creating abstract patterns, shapes, and illusions that dance across the stage. The soundtrack should be ambient and minimalist, enhancing the atmospheric and abstract nature of the piece.
(这是一部纯粹以视觉和氛围见长的影像作品,核心聚焦光影的交织互动,以玉米列车为中心意象。试想一个舞台,被富有戏剧张力的暖调聚光灯笼罩,一列玉米列车化作鲜明的剪影,在空间中缓缓穿行。影片探寻列车投下的光影所形成的动态呼应——它们在舞台上舞动,幻化出抽象的图案、形态与视觉幻象。配乐应采用氛围化的极简风格,以此强化作品的氛围感与抽象特质。)
视频输出的gif截取:

背后,生成这些视频的生成模型有什么技术创新点?这要从视频生成模型在扩展规模(scale-up)时面临的挑战说起,主要原因在于视频生成需要处理的视频token长度远超过文本和图像,这导致计算资源消耗巨大,难以支撑大规模模型的训练与部署。
混合专家模型(MoE)架构作为一种广泛应用于大型语言模型领域的模型扩展方式,通过选择专门的专家模型处理输入的不同部分,扩种模型容量却不增加额外的计算负载。
1、首个MoE架构的视频生成模型,高噪+低噪专家模型“搭档”
万相2.2模型将MoE架构实现到了视频生成扩散模型(Diffusion Model)中。考虑扩散模型的去噪过程存在阶段性差异,高噪声阶段关注生成视频的整体布局,低噪声阶段则更关注细节的完善,万相2.2模型根据去噪时间步进行了专家模型划分。
相比传统架构,通义万相Wan2.2 MoE在减少计算负载的同时有哪些关键效果提升?业界首个使用MoE架构,团队主要攻克了哪些难点?
通义万相团队相关负责人告诉智东西,团队并不是将语言模型中的MoE直接套用到视频模型,而是用适配了视频生成扩散模型的MoE架构。该架构将整个去噪过程划分为高噪声和低噪声两个阶段:在高噪声阶段,模型的任务是生成视频大体的轮廓与时空布局;在低噪声阶段,模型主要是用来细化细节纹理和局部。每个阶段对应一个不同的专家模型,从而使每个专家专注特定的任务。
“我们的创新点是找到高阶噪声和低噪声阶段的划分点。不合理的划分会导致MoE架构的增益效果不足。我们引入了一个简单而有效的新指标——信噪比来进行指导,根据信噪比范围对高噪和低噪的时间T进行划分。通过这种MoE的架构,我们总参数量相比于2.1版本扩大了一倍,但训练和推理每阶段的激活值还是14B,所以整体的计算量和显存并没有显著增加,效果上是有效的提升了运动复杂运动和美学的生存能力。”这位负责人说。

▲万相2.2的28B版本由高噪专家模型和低噪专家模型组成
2、数据扩容提高生成质量,支撑与美学精调
较上一代万相2.1模型,万相2.2模型的训练数据实现了显著扩充与升级,其中图像数据增加65.6%,视频数据增加83.2%。数据扩容提升了模型的泛化能力与创作多样性,使得模型在复杂场景、美学表达和运动生成方面表现更加出色。
模型还引入了专门的美学精调阶段,通过细粒度地训练,使得视频生成的美学属性能够与用户给定的Prompt(提示词)相对应。
万相2.2模型在训练过程中融合了电影工业标准的光影塑造、镜头构图法则和色彩心理学体系,将专业电影导演的美学属性进行了分类,并细致整理成美学提示词。
因此,万相2.2模型能够根据用户的美学提示词准确理解并响应用户的美学需求。训练后期,模型还通过强化学习(RL)技术进行进一步的微调,有效地对齐人类审美偏好。
3、高压缩比视频生成,5B模型可部署消费级显卡
为了更高效地部署视频生成模型,万相2.2探索了一种模型体积更小、信息下降率更高的技术路径。
通义万相Wan2.2开源5B版本消费级显卡可部署,该设计如何平衡压缩率与重建质量?
通义万相团队相关负责人告诉智东西,为了兼顾性能与部署的便捷性,wan 2.2版本开发了一个5B小参数版。这一版本比2.1版本的14B模型小了一半多。同时团队采用了自研高压缩比VAE结构,整体实现了在特征空间上16×16的高压缩率,是2.1版本压缩率(8×8)的四倍,从而显著降低了显存占用。
为了解决高压缩比带来的问题,团队在这个VAE的训练中引入了非对称的编码结构以及残差采样机制;同时其还增加了这个隐空间的维度,把原来的2.1版本的16位增加到了48位。这样使模型在更大的压缩率下保持了良好的重建质量。
此次开源的5B版本采用了高压缩比VAE结构,在视频生成的特征空间实现了视频高度(H)、宽度(W)与时间(T)维度上32×32×4的压缩比,有效减少了显存占用。5B版本可在消费级显卡上快速部署,仅需xx显存即可在xx秒内生成5秒720p视频。此外,5B版本实现了文本生成视频和图像生成视频的混合训练,单一模型可满足两大核心任务需求。
此次开源中,万相2.2也同步公开了全新的高压缩比VAE结构,通过引入残差采样结构和非对称编解码框架,在更高的信息压缩率下依然保持了出色的重建质量。
二、60+专业参数引入,实现电影级美学控制本次,阿里通义万相团队还推出了“电影级美学控制系统”,通过60+专业参数赋能, 将专业导演的光影、色彩、镜头语言装进生成模型。用户通过直观选择美学关键词,即可智能生成电影质感的视频画面。
许多创作者都遇到过这样的难题:明明脑海中有充满电影感的画面,如王家卫式的霓虹夜晚、诺兰式的硬核实景、韦斯·安德森式的对称构图,实际生成的效果却总差强人意——光线平淡像随手拍、构图随意缺乏张力、色调混乱没有氛围。
通义万相团队认为,根本原因在于,真正的电影感源于对光影、色彩、镜头语言三大美学体系的精密控制。这些专业能力以往需要多年的学习和实践才能掌握。wan 2.2的全新功能可以解决这一核心痛点。
智能美学词响应是系统的核心创新。用户无需理解复杂的电影术语,只需在中文界面选择想要的美学关键词,如黄昏、柔光、侧光、冷色调、对称构图、特写等,系统将自动理解并精确响应,在后台智能调整灯光属性、摄像机参数、色彩滤镜等数十项技术指标。

在文生视频领域,生成基础、平缓的动作已非难事,但如何生成大幅度、高复杂度、高细节的动作,如街舞、体操等,始终是技术跃迁的关键挑战。
Wan2.2模型针对面部表情,手部动作,单人、多人交互、复杂动作等方面进行了专门优化,大幅提升了细微表情、灵巧手势、单人与多人交互、复杂体育运动等生成能力。
比如,Wan2.2构建了人类面部原子动作和情绪表情系统。它不仅能生成如“开怀大笑”、“轻蔑冷笑”、“惊恐屏息”等典型情绪表达,更能细腻刻画“羞涩微笑中的脸颊微红”、“思考时不经意的挑眉”、“强忍泪水时的嘴唇颤抖”等复杂微表情,从而精准传达复杂的人物情绪与内心状态。
比如,Wan2.2还构建了丰富的手部动作系统,能够生成从力量传递的基础物理操作、精细器具交互的复杂控制,到蕴含文化语义的手势符号体系,乃至专业领域的精密动作范式等手部动作。
此外值得一提的是,Wan2.2模型针对多项基础物理定律与现象进行了优化。这包括对力学、光学以及流体力学和常见物理状态变化的学习,力求构建高度真实的物理基础。
在复杂动态场景的处理上,Wan2.2专门优化了多目标生成与交互场景。它能够稳定地生成多个独立物体或角色同时进行的复杂动作及其相互影响。此外,Wan2.2 对复杂空间关系的理解与呈现也得到大幅增强,能够精确理解物体在三维空间中的相对位置、距离、深度、遮挡的空间结构变化。
结语:突破视频模型规模瓶颈,推动AI视频生成专业化演进Wan2.2首创MoE架构视频生成模型,为突破视频模型规模瓶颈提供了新路径;5B版本大幅降低高质量视频生成门槛,加速生成式AI工具普及。
“电影级美学控制”将专业影视标准体系化融入AI,有望推动AI视频生成工具向更加专业化的方向发展,助广告、影视等行业高效产出专业内容;其复杂运动与物理还原能力的提升,显著增强了生成视频的真实感,为教育、仿真等多领域应用奠定基础。
灵菲配资-配资炒股配资优秀-配资网官网最新信息-配资上市公司一览表提示:文章来自网络,不代表本站观点。


